Algorithms for Specific Hardware
Home
About Us
People
Teaching
Research
Publications
Awards
Links
Contact
Internal
We are surrounded be embedded systems like mobile phones and
PDAs, and by special hardware such as game consoles or GPUs.
While embedded portable systems often have very limited ressources,
game consoles or GPUs may even offer interesting possibilities
for efficient parallel computing.
Many of the methods in our group are based on mathematically involved
concepts such as nonlinear partial differential equations or variational
methods. In order to demonstrate that our algorithms can cope with
very limited ressources on one hand, and that they are well-suited
for modern parallel architectures on the other hand, we also develop
prototypical implementations on these types of hardware.
Working on specialised hardware requires a deep insight into
the structure and principles of the underlying device. Often
such machines make it necessary to devise entirely new approaches to
well-known problems, or demand novel formulations of existing
algorithms.
Our work concentrates on three types of hardware:
-
Mobile phones and other portable devices have become a central part of everyday life. Often, they are not solely used for communication, but provide the user with a variety of features: Office applications and e-book readers make it possible to access, edit and share one's documents anywhere on the world. Integrated cameras and multimedia applications, combined with a direct connectivity to social networks on the internet, immediately link the user to these virtual services.

We support these developments by the design of image processing algorithms for mobile platforms. In this way, it is possible to enhance images directly when they are captured from the camera, and to preproccess them for their further application in other programs or on the internet.
Typically mobile architectures are challenging in many ways. As a technical restriction, software cannot be developed on the device, but needs to be written and compiled in external toolchains. However, also from an algorithmic side, mobile processors require dedicated adaptations of the code: Often they do not possess floating point units, which then forces the programmer to rewrite algorithms with fixed point computations. Memory is usually very limited, and the concept of virtual memory and swapping is not implemented. In turn, algorithms need to be optimised with respect to their memory requirements. Finally, also the communication and data exchange with the operating system has to be revised, since mobile systems often provide different interfaces, or require applications to integrate into a rigid framework. -
The Sony PlayStation 3 is one of the cheapest parallel computers available on the consumer market. It does not set up on a traditional CPU architecture, but possesses a so-called Cell Broadband Engine processor. This chip was specially designed for its use in the high-end video console, and is therefore about six times as powerful as a standard CPU core. We exploit this performance for our parallel real-time optic flow algorithms, which we devise and optimise for this architecture.

The Cell processor of a PlayStation 3 consists of eight 'synergistic' cores (SPUs), which are meant for pure computations, supplemented by one general-purpose core, the PPU. Different to traditional multi-core desktop CPUs, however, the SPUs are not automatically controlled and managed by the operating system. Instead, they require the programmer to explicitly design bus protocols for the communication, to manually synchronise their on-chip memory with the RAM, and to load and dispatch the kernels on the respective cores. For this purpose, programs are written in a superset of the C programming language which allows the programmer to access special control registers. -
Graphics hardware (GPU) is today an inexpensive but extremely powerful platform for parallel algorithms. Using the Compute Unified Device Architecture (CUDA) framework developed by Nvidia Corp., we design efficient algorithms for diffusion processes, image compression, optic flow, and shape from shading.

Unlike for desktop processors, where programs typically do not need to scale onto more than eight cores, GPUs usually require the developer to split his algorithm into hundreds of threads. These are then processed with a high degree of parallelism, which makes programmes extremely fast. Compared to desktop architectures, speedups of one or even two orders of magnitude can be obtained.
Since some traditional approaches to problems in visual computing are no longer justified on this architecture, we will propose alternative methods that respect the pecularities of the device. Thereby, we also consider and circumvent typical bottlenecks entailed by the special memory hierarchy, or the rather slow connectivity to the CPU. Our findings will be validated by the speedups we obtain compared to traditional hardware.
Part of our research on algorithms for mobile phones and the Playstation 3 is in collaboration with Professor Michael Schreiner (Buchs, Switzerland).
-
Coherence-Enhancing Shock Filters on a Mobile Phone.
Coherence-enhancing shock filters are based on nonlinear hyperbolic partial differential equations. They perform dilation around maxima and erosion around minima, where the influence zone of these extrema is determined by the so-called structure tensor [1]. When applied to images of humans, coherence-enhancing shock filters can create interesting caricatures:


As a demonstrator that it is even possible to solve nonlinear hyperbolic partial differential equations on a mobile phone, we have developed an implementation of a coherence-enhancing shock filter on a Nokia N80 phone. With this implementation one can take a digital image of a person and create a caricature within a few seconds [2]. -
Barcode Reading on a Mobile Phone.
Classical barcode scanners are fairly expensive. In [3] we exploit an inexpensive alternative where pattern recognition and image processing methods are implemented on a mobile phone. This involves several morphological image enhancement methods. -
Fast PDE-Based Diffusion and Optic Flow on Android Smartphones.
On mobile devices, people often shy away from using PDE-based algorithms for realtime applications, because they are said to be too slow for such architectures. In [12] we show that these concerns are unjustified. We propose realtime-capable algorithms for linear and nonlinear diffusion, as well as an interactive variational optic flow algorithm for Android smartphones. This work opens doors for a range of interesting applications such as low-light imaging, super-resolution, HDR imaging, or structure from motion.
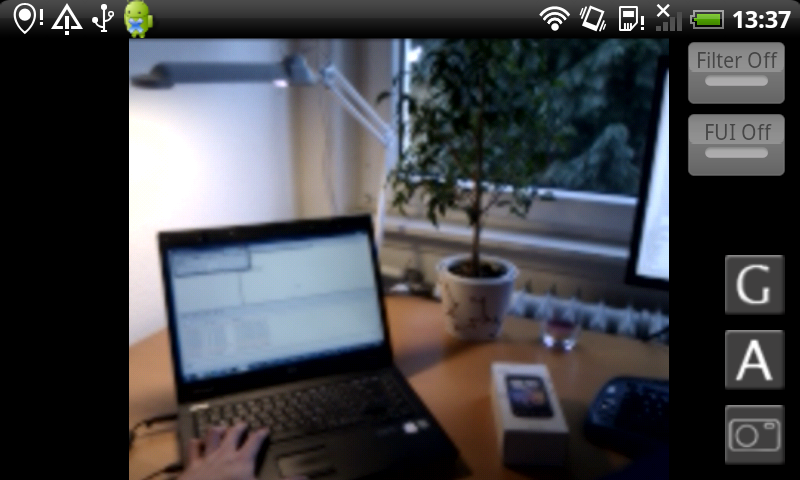
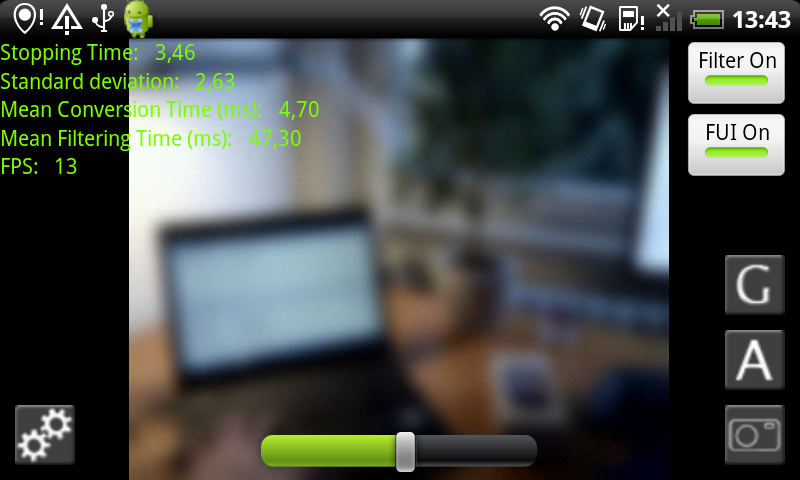
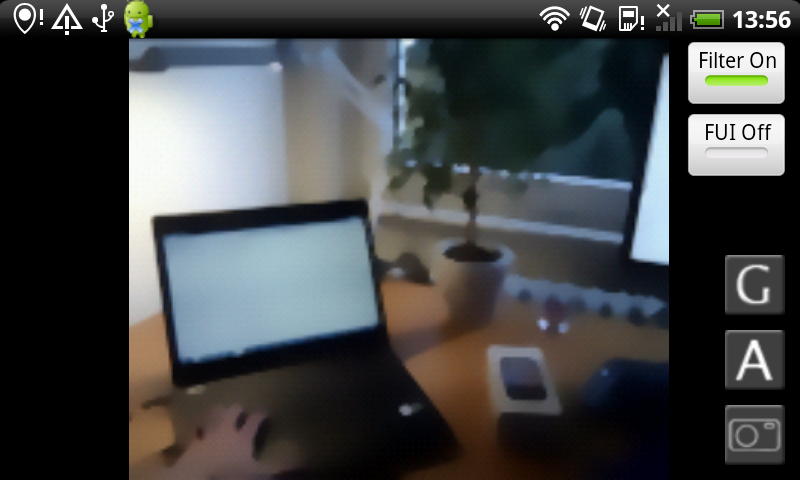

-
PDE-Based Realtime Image Inpainting on the iPhone 4.
Modern smartphones enjoy a reasonable computational power, but suffer from relatively low data bandwidth to connect to the internet. PDE-based video compression techniques offer a remedy to this problem, since they are among the leading methods to obtain high compression rates in a given quality. However, decoding this information is expensive, and could result in low frame rates on mobile devices. In [13], we present a realtime algorithm for homogeneous image inpainting on the iPhone 4. By using efficient numerics, we demonstrate that today's smartphones can easily decode videostreams that were compressed by PDE-based techniques.Please enable Javascript and Flash to see the video -
Variational Deconvolution Methods on the Sony Playstation 3.
Variational deconvolution methods are computationally more demanding than many other variational approaches in image analysis, since the blurring kernel creates additional nonvanishing entries in the system matrix. Therefore, we have used a quadratic variational deconvolution approach as a test case for parallelisation strategies on a Playstation 3 [4]. -
Variational Optic Flow Methods on the Sony Playstation 3.
Modern variational methods for optic flow computation offer dense flow fields and highly accurate results, but their computational complexity has prevented their use in many real-time applications. For a linear [5] and a nonlinear variant [6] of the popular combined local-global (CLG) method [7], we present specific algorithms that are tailored towards real-time performance. They are based on bidirectional full multigrid methods with a full approximation scheme (FAS) in the nonlinear setting. Their parallelisation on the Cell hardware uses a temporal instead of a spatial decomposition, and processes operations in a vector-based manner. Memory latencies are reduced by a locality-preserving cache management and optimised access patterns. With images of size 316 x 252 pixels, we obtain dense flow fields for up to 210 frames per second. -
AOS Schemes for 3D Isotropic Nonlinear Diffusion on a GPU.
Semi-implicit finite difference discretisations of nonlinear diffusion processes with a scalar-valued diffusivity create very large systems of linear equations. In [9] it is shown how they can be solved efficiently on GPUs using additive operator splitting (AOS) techniques (see e.g. [8]). -
Eight-voxel schemes for 3D Anisotropic Nonlinear Diffusion
on a GPU.
Locally semi-analytic schemes (LSAS) are simple, absolutely stable numerical methods for anisotropic diffusion filtering with a diffusion tensor [10]. Their intrinsic parallelism makes them attractive for CUDA implementations on GPUs [11].
-
J. Weickert:
Coherence-enhancing shock filters.
In B. Michaelis, G. Krell (Eds.): Pattern Recognition. Lecture Notes in Computer Science, Vol. 2781, Springer, Berlin, 1-8, 2003. -
T. Krattinger:
Hochleistungsarithmetik auf einem Mobiltelefon.
Diploma thesis, Interstate University of Applied Sciences of Technology Buchs, NTB, Switzerland, 2005. -
Y. Yuan:
Design and implementation of a camera-based bar code recognition software for windows mobile devices.
Diploma thesis in Computer Science, Saarland University, 2007. -
R. Nadig, T. Spirig:
Parallelisierung auf dem Cell-Prozessor.
Diploma thesis, Interstate University of Applied Sciences of Technology Buchs, NTB, Switzerland, 2007. -
P. Gwosdek, A. Bruhn, J. Weickert:
High performance parallel optical flow algorithms on the Sony Playstation 3.
In O. Deussen, D. Keim, D. Saupe (Eds.): Vision, Modeling, and Visualization 2008, AKA, Heidelberg, 253-262, October 2008. -
P. Gwosdek, A. Bruhn, J. Weickert:
Variational optic flow on the Sony PlayStation 3 - Accurate dense flow fields for real-time applications.
Journal of Real-Time Image Processing, in press.
Revised version of Technical Report No. 233, Department of Mathematics, Saarland University, Saarbrücken, Germany, March 2009. -
A. Bruhn, J. Weickert, C. Schnörr:
Lucas/Kanade meets Horn/Schunck: Combining local and global optic flow methods.
Updated version with errata. International Journal of Computer Vision, Vol. 61, No. 3, 211-231, February/March 2005.
-
J. Weickert, B.M. ter Haar Romeny, M.A. Viergever:
Efficient and reliable schemes for nonlinear diffusion filtering.
IEEE Transactions on Image Processing, Vol. 7, 398-410, 1998. -
S. Pushkarev:
3-D Nonlinear Diffusion Filtering on GPUs Using an AOS Scheme.
M.Sc. thesis in Computer Science, Saarland University, Saarbrücken, Germany, 2009. -
M. Welk, G. Steidl, J. Weickert:
Locally analytic schemes: a link between diffusion filtering and wavelet shrinkage.
Applied and Computational Harmonic Analysis, Vol. 24, 195–224, 2008. -
T. Becker:
Eight-Voxel Schemes for Anisotropic Diffusion in 3D: Efficient Implementation and Evaluation.
M.Sc. thesis in Visual Computing, Saarland University, Saarbrücken, Germany, 2009. -
A. Luxenburger, H. Zimmer, P. Gwosdek, J. Weickert:
Fast PDE-based image analysis in your pocket.
To appear in Proc. Third International Conference on Scale Space and Variational Methods in Computer Vision (SSVM 2011, Ein-Gedi, Israel, May 29 - June 2, 2011). -
L. Keller:
PDE-Based Image Reconstruction on the iPhone 4.
B.Sc. thesis in Mathematics, Saarland University, Saarbrücken, Germany, 2011.
MIA Group
©2001-2023
The author is not
responsible for
the content of
external pages.
Imprint -
Data protection