Complementary Optic Flow on the GPU
Home
About Us
People
Teaching
Research
Publications
Awards
Links
Contact
Internal
Results
Runtimes
In order to reason about the scaling of our algorithm over varying image sizes,
we compute the results for many input images and visualise the runtimes in a
graph. Since implementations for certain operators are more efficient in one
direction than in the other and frames captured from an input device is
typically of ratio 4:3, we choose this format for comparison. However, please
note that our algorithm runs even faster on squared images.
As for all experiments presented on these web pages, we show the results
obtained on a Sparkle GeForce GTX 480. These are slightly faster than the
results in our paper, which were performed on a GTX 285.
In the figure below, two different graphs are shown. One only covers the pure
computation, i.e. the time needed to compute a solution once the problem has
been uploaded to the device. The second graph additionally takes into account
the up- and downloading phase. It should be considered if the problem resides
on the CPU, and if the solution must be postprocessed on the CPU as well.
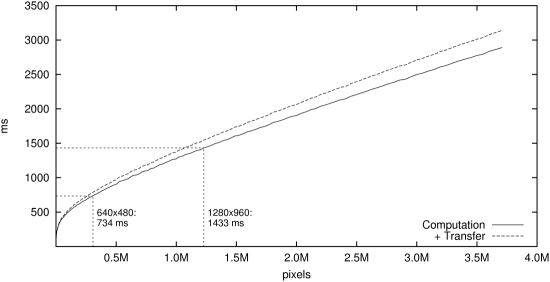
The shape of the graph gives interesting insights to the efficiency of our
algorithm. Apart from very small frames, where the GPU capacity cannot be fully
used due to a small parallelism of the problem, our implementation scales
almost linear with the number of pixels. Typical screen resolutions can be
computed in about 1–1.5 seconds, and even Full HD frames
(1920×1080, with a ratio of 16:9 instead of 4:3) take less than two
seconds to compute. However, the restricted RAM resources of our graphics card
(1.5 GiB) limit the maximal frame size to 3.7 MPx.
As grey images occupy less memory than their RGB counterparts and also require
less operations, both the runtime performance and the maximal frame size can be
enhanced if we consider one-channel images only. This is depicted in the graph
below.
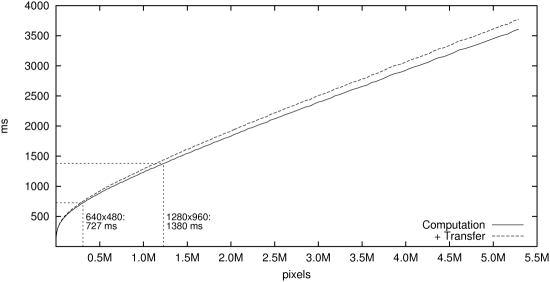
Again, we distinguish the pure runtime and additional transfer costs.
Note that in comparison to the RGB case, the latter are reduced since only two
instead of six matrix-valued images need to be transferred to the device.
Moreover, the much lower RAM consumption also enables the algorithm to compute
larger frames up to 5.3 MPx.
MIA Group
©2001-2023
The author is not
responsible for
the content of
external pages.
Imprint -
Data protection